New 5 Best Big data platforms: beyond Hadoop

Over the last few decades, Big data has become synonymous to Hadoop. Hadoop is sure to pop-up when talking about big data in any conversation. Since we are all aware of the rapid development that is taking place in technology, Big Data encloses a wide array of option. And Hadoop is just one among those.
Other than Hadoop, here we have discussed the five best big data platforms that should be given priority.
Basically, it is a type of IT solution which merges the capabilities and features of numerous big data application within a single solution. This class IT platform enables the organisation in deploying, developing, managing and operating a significant data environment/infrastructure.
Usually, it consists of servers, data storage, big data management, database, business intelligence and other big management utilities. Also, it supports custom development, integration and queries with other systems. Reduction of the complexity of multiple vendors is the primary benefit behind a big data platform. Some of its features include:
- Support linear scale-out
- Support a variety of data format
- Real-time data analysis software
- Tools for searching through large data sets
- Capability for rapid deployment
- Accommodation of new platforms and tool based on business needs.
- A platform should provide reporting tools and data analysis
Although Hadoop is not exactly suffering from an increase in competition at this point, organisations are beginning to understand that Big Data comprises more than Hadoop development. Listed below are top 5 alternatives that have evolved in Big Data Space.
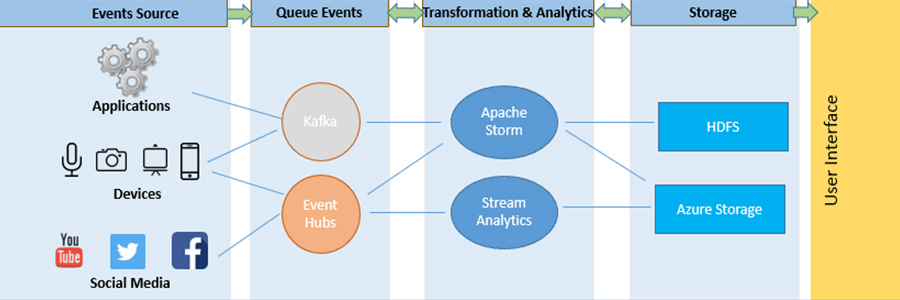
- Written predominantly in the Clojure programming language, Apache Storm is a stream processing computation framework. Initially, it was created at BackType by Nathan Marz, and the project became open-sourced after it was taken over by Twitter. To define information sources, it uses custom made “bolts” and “spouts” along with manipulations to enable batch, distribute processing of streaming data. The date of the initial release was on 17th Sep 2011.
- Generally, a storm application is designed as a “topology” in the shape of DAG (directed acyclic gap) with bolts and spouts resembling graph vertices. On the edges of the graph, streams and direct data are named from one node to another — the topology as a whole act as a data transformation pipeline.
- At a superficial level, the structure of topology shows similarity to a MapReduce job. However, the main difference lies in the processing of data. The data is processed in real-time as opposed to individual batches. While MapReduce job DAG eventually ends, Storm topology runs indefinitely until killed.

- DataTorrent RTS or DataTorrent Real-time Streaming, a batch processing platform and Hadoop-native unified stream, is an enterprise product built around Apache Apex. Here, Apache Apex is combined with a set of enterprise- monitoring, grade management, visualisation tools, and development.
- It comes with various new features that provide capabilities to make it easier for customers to analyse, explore, and visualise trends in data.
- For becoming more customer-centric, create new revenue streams and improve operational performance, companies are aware of the need to gain insight from data. Nowadays, updates are not only built to cater to the needs of organisations but also to fundamentally change the way big data applications are deployed, designed, and managed.
DataTorrent RTS platform provides management and creation of real-time big data applications in a way that is:
- fault-tolerant should recover automatically without any data or state loss.
- Hadoop native- installing within seconds and works with all Hadoop distributions.
- Highly performant and scalable- with linear scalability, millions of events per second per node.
- Quickly operable- a full suite of monitoring, management, visualisation tools and development.
- Quickly developed- re-use and write generic Java code
- Easily integrated- customizable connectors to the database, messaging systems, and file.

- Ceph is a software storage platform that aims to implement object storage on a single distributed computer network and provides connexions for block-, file- and object-level storage. One of its primary objectives is to distribute operation entirely without a single point of error, freely available, and scalable to the Exabyte level.
- What Ceph does is, replicates data making it fault-tolerant, using commodity hardware without requiring any specific hardware support. Because of the system’s design, it’s self-managing and self-healing. It focuses on minimising administration time and other costs that are attributed to it.
- The Ceph development team released Jewel on 21st April 2016. It is the first release of Ceph which is considered stable since it comprises of CephFS. The disaster and repair recovery tools of CephFS are considered feature-complete with multiple active me data servers, snapshots and other default disabled functionalities.
- Me data server has the ability to contract or expand and is able to rebalance the file system. Within the cluster, high performance is ensured, and heavy load on specific hosts is prevented.

- For running interactive analytic queries against data sources, Presto is an open-source distributed SQL engine. The data sources can be of any type ranging from petabytes to gigabytes. From the ground, it was written and designed for interactive analytics. While scaling to the size of organisations like Facebook, it approaches the speed of commercial warehouses.
- Also, it allows querying data where it lives, including Cassandra, relational databases, Hive, or even proprietary data stores. One single Presto query can comprise of combined data from multiple sources by allowing for data analysis across the entire organisation.
Presto is suitable for analysts who expect a response within sub-second or minutes. - Initially, it was developed and designed by Facebook to run interactive queries for their data analysis. Presto was created to fill the gap that the Apache Hive has had formed due to its inefficiency.

- Hydra is a storage and distributed data processing system that absorbs streams of data and builds trees as well that are summaries, transformations, or aggregates of the data. Humans can use these trees to explore, support lives consoles on websites, as a part o machine learning pipeline. Hydra is able to tackle some essential data that Hadoop struggles to deal with.
- You are allowed to run Hydra from the command line to slice and dice. Run a Hydra Cluster if terabytes per day are your cup of tea. Hydra Cluster supports it with resource sharing, distributed backups, job management, efficient bulk file transfer, and data partitioning. It can use HDFS, but it operates on native file systems as well.
- Developed by social bookmarking service AddThis, Hydra delivers real-time analysis of data to customers. At that time, AddThis was in need of a scalable distributed system and Hadoop wasn’t an option at that time, which led to the creation of Hydra.
Though Hadoop has tremendous power and benefits, it does possess some drawbacks. It’s not always considered as the most efficient while dealing with Big Data development solutions and unstructured data processing which calls for the need for alternatives. Day by day, the associated between Hadoop and Big Data is becoming looser and more choices are beginning to get developed. The other options have proved to be the better option with speed advantages or by making efficient use of hardware.